
Imagine a single web request that has to call three downstream services — a user service, an orders service, and a recommendations service — and combine their answers. Run them one after another and your user waits for the sum of all three. Run them at the same time and the request is only as slow as the slowest call. The catch is that "run them at the same time" has, for twenty years, been where Java code quietly turned fragile: threads leak, a failure in one call doesn’t stop the others, and a thread dump tells you nothing about which task started which.
Structured concurrency is the feature that fixes this. It treats a group of related tasks running in different threads as a single unit of work — they start together, they finish together, and if one fails the rest are cancelled automatically. This post starts from zero (if you’ve only ever written single-threaded Java, you’re fine) and ends at reference-grade detail: custom joiners, timeouts, observability, and the JDK 25/26 API exactly as it stands today.
Status (June 2026): Structured concurrency is a preview API. It previewed most recently in JDK 25 (JEP 505) and JDK 26 (JEP 525), and finalization is widely expected around JDK 27. Every example below targets JDK 26 and must be compiled and run with preview features enabled (shown later). The shape of the API is stable; only small details still move between previews.
The problem: "unstructured" concurrency
Here is the classic way to fan out two calls with an ExecutorService, the API we’ve had since Java 5:
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = executor.submit(() -> findUser());
Future<Integer> order = executor.submit(() -> fetchOrder());
String theUser = user.get(); // join findUser
int theOrder = order.get(); // join fetchOrder
return new Response(theUser, theOrder);
}It looks innocent, but think through what happens when things go wrong:
- If
findUser()throws,user.get()throws — butfetchOrder()keeps running in its own thread. That’s a thread leak: at best it wastes resources, at worst it interferes with later work. - If the thread running
handle()is interrupted, that interruption is not propagated to the two subtasks. Both keep running. - If
findUser()is slow andfetchOrder()has already failed, you still block onuser.get()and learn about the failure late.
The root cause is that ExecutorService and Future allow unrestricted concurrency. One thread can submit work, a different thread can await it, and nothing records that findUser and fetchOrder are children of the same handle task. The task-subtask relationship lives only in your head — so the runtime can’t help you with cancellation, error propagation, or observability.
The idea: make task structure mirror code structure
Now look at the single-threaded version of the same method:
Response handle() throws IOException {
String theUser = findUser();
int theOrder = fetchOrder();
return new Response(theUser, theOrder);
}Here the structure is obvious and free: findUser() and fetchOrder() are subordinate to handle(), they can only return to handle(), and if findUser() throws, fetchOrder() never even starts. The call stack is the task hierarchy.
Structured concurrency brings that same guarantee to multiple threads. Its founding principle is one sentence:
If a task splits into concurrent subtasks, they all return to the same place — the task’s own code block.
Because the subtasks’ lifetimes are nested inside the enclosing block, the runtime can reason about them as a unit: apply a deadline to the whole group, cancel siblings when one fails, and show the hierarchy in a thread dump. This is the same leap structured programming made when it replaced goto with blocks, loops, and functions — now applied to threads.
One prerequisite: virtual threads
Structured concurrency is built on virtual threads (finalized in JDK 21, JEP 444). A virtual thread is a lightweight thread managed by the JVM rather than the OS, so you can have millions of them and it’s perfectly fine to dedicate one to every single subtask — even ones that just sit and wait on I/O. By default, every subtask you fork runs in its own fresh virtual thread. You don’t manage a pool, you don’t size anything; the scope owns the threads and guarantees they’re gone when the block exits. Keep this in mind: structured concurrency is "cheap threads" plus "strict lifetimes."
Your first StructuredTaskScope
The principal class is java.util.concurrent.StructuredTaskScope. Here is the handle() example rewritten — this is the canonical structured-concurrency program:
import java.util.concurrent.StructuredTaskScope;
import java.util.concurrent.StructuredTaskScope.Subtask;
record Response(String user, int order) {}
class Server {
String findUser() throws InterruptedException {
Thread.sleep(120); // pretend: a network call
return "Alice";
}
int fetchOrder() throws InterruptedException {
Thread.sleep(80); // pretend: another network call
return 42;
}
Response handle() throws InterruptedException {
try (var scope = StructuredTaskScope.open()) { // 1. open
Subtask<String> user = scope.fork(this::findUser); // 2. fork
Subtask<Integer> order = scope.fork(this::fetchOrder); // fork
scope.join(); // 3. wait for BOTH, propagate any failure
return new Response(user.get(), order.get()); // 4. process results
} // 5. close: cancel + wait (automatic)
}
public static void main(String[] args) throws InterruptedException {
System.out.println(new Server().handle());
}
}Compile and run it with preview features enabled:
$ javac --release 26 --enable-preview Server.java
$ java --enable-preview Server
Response[user=Alice, order=42]Read that try block as a contract. Under all conditions the two threads’ lifetimes are confined to the body of the try-with-resources statement. From that single guarantee you get four valuable properties — and each one is exactly the pain point from the unstructured version, now solved:
- Error handling with short-circuiting — if
findUser()fails,fetchOrder()is cancelled (interrupted) if it hasn’t finished, and vice versa. - Cancellation propagation — if the thread running
handle()is interrupted, both subtasks are cancelled automatically as the scope closes. - Clarity — set up subtasks, wait, then decide success or failure. No manual
try/finally, no jugglingFuture.cancel(...). - Observability — a thread dump shows
findUserandfetchOrderas children of the scope (more on this below).
The lifecycle: open → fork → join → process → close
Every scope walks through the same five stages, and it helps to hold the whole picture in your head before we vary the details:
- open — call a static
open(...)method, ideally in atry-with-resources. The thread that opens it is the scope’s owner. - fork — submit each subtask with
scope.fork(...). Each one starts immediately in its own virtual thread and returns aSubtaskhandle. - join — the owner calls
scope.join()exactly once, blocking until the scope’s completion policy is satisfied (all done, first success, timeout, …). - process — after
join()returns, read results from theSubtaskhandles, which are now guaranteed complete. - close — usually implicit via
try-with-resources. Closing cancels anything still running and waits for every thread to terminate, so no thread is ever left behind.
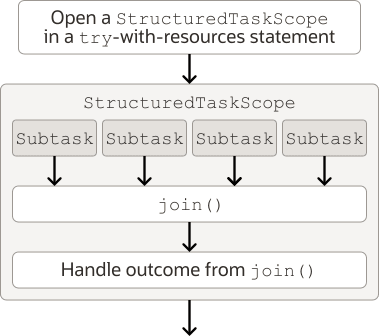
Two rules follow from this lifecycle and are worth memorizing early: fork and join may be called only by the owner thread, and you must call join before reading any Subtask.get(). Calling get() too early throws an exception, because the result genuinely isn’t ready yet.
Choosing a policy with Joiners
So far we used the zero-argument open(), whose default policy is "wait for all subtasks; if any fails, cancel the rest and throw; otherwise return null." That’s the right default, but many real tasks want a different rule — "give me the first one that answers," or "collect every successful result." You select a policy by passing a Joiner to open. A joiner decides how completions are handled and what join() ultimately returns.
The built-in joiners (as of JDK 26) cover the common cases:
Joiner.… factory |
What scope.join() does |
|---|---|
awaitAllSuccessfulOrThrow() |
Wait for all to succeed; throw on the first failure. Returns null. (Same policy as the default open().) |
allSuccessfulOrThrow() |
Wait for all to succeed; throw on the first failure. Returns a List of the results. |
anySuccessfulOrThrow() |
Return the result of the first subtask to succeed; cancel the rest. Throw only if all fail. |
awaitAll() |
Wait for all to finish, success or failure. Never throws. Returns null. |
allUntil(Predicate) |
Wait until all complete or your predicate says "enough," then return the list of all subtasks. |
Run them all and collect results
When every subtask returns the same type and you want all the answers, use allSuccessfulOrThrow() — in JDK 26 it hands you a tidy List:
<T> List<T> runConcurrently(Collection<Callable<T>> tasks) throws InterruptedException {
try (var scope = StructuredTaskScope.open(Joiner.<T>allSuccessfulOrThrow())) {
tasks.forEach(scope::fork);
return scope.join(); // List<T> of results; throws if any task fails
}
}Race for the first answer
When you have several redundant sources and want whichever replies first — a classic latency trick — use anySuccessfulOrThrow():
<T> T race(Collection<Callable<T>> tasks) throws InterruptedException {
try (var scope = StructuredTaskScope.open(Joiner.<T>anySuccessfulOrThrow())) {
tasks.forEach(scope::fork);
return scope.join(); // result of the first subtask to succeed
}
}The moment one subtask succeeds, the scope is cancelled, the slower siblings are interrupted, and join() returns the winner. If every subtask fails, join() throws a FailedException.
A practical example you can run: five tasks that each sleep a random amount and throw if they’re "too slow." With allSuccessfulOrThrow(), a fully successful run prints something like —
Duration: 471
Duration: 77
Duration: 191
Duration: 31
Duration: 347
Result: 77
Result: 471
Result: 191
Result: 31
Result: 347— and a run where one task exceeds the threshold short-circuits the rest:
Duration: 996
Duration: 518
Duration: 937
FailedException: TooSlowException: Duration 996 greater than threshold 700(Both outputs are from Oracle’s JDK 26 example; durations are random, so yours will differ.)
Handling failures
When a scope is considered failed, join() throws a StructuredTaskScope.FailedException whose getCause() is the original exception from the failed subtask. Because you handle it after the scope has closed, all sibling threads are already cancelled and joined — there is nothing left to clean up. Pattern matching makes the handling crisp:
try (var scope = StructuredTaskScope.open()) {
Subtask<String> user = scope.fork(this::findUser);
Subtask<Integer> order = scope.fork(this::fetchOrder);
scope.join();
return new Response(user.get(), order.get());
} catch (StructuredTaskScope.FailedException e) {
Throwable cause = e.getCause();
switch (cause) {
case java.io.IOException ioe -> log.warn("I/O failed", ioe);
default -> log.error("Unexpected", cause);
}
throw e;
}If a particular failure should instead yield a default value, prefer catching it inside the subtask and returning the default — that keeps the scope’s success/failure logic simple and intentional.
Timeouts and configuration
A third open overload accepts a configuration callback, letting you name the scope, set a deadline for the whole group, or supply a custom thread factory. Notice how this builds directly on the policy idea — the joiner decides what counts as done, and the timeout decides how long the group is allowed to take:
<T> List<T> runConcurrently(Collection<Callable<T>> tasks,
ThreadFactory factory,
Duration timeout) throws InterruptedException {
try (var scope = StructuredTaskScope.open(
Joiner.<T>allSuccessfulOrThrow(),
cf -> cf.withName("orders")
.withThreadFactory(factory)
.withTimeout(timeout))) {
tasks.forEach(scope::fork);
return scope.join();
}
}If the timeout fires before join() is satisfied, the scope is cancelled (all incomplete subtasks interrupted) and join() throws a StructuredTaskScope.TimeoutException. The deadline applies to the entire sub-tree of work — exactly the kind of policy that’s awkward to express with raw futures.
Writing a custom Joiner
The built-in joiners are an "all or nothing" family. Sometimes you want something in between — for example, collect whatever succeeds and silently ignore failures. Implement the Joiner<T, R> interface, where T is the subtask result type and R is what join() returns:
public interface Joiner<T, R> {
default boolean onFork(Subtask<T> subtask) { return false; }
default boolean onComplete(Subtask<T> subtask) { return false; }
void onTimeout(); // invoked if the scope's timeout fires
R result() throws Throwable; // produces join()'s return value
}onFork and onComplete return a boolean that says "should the scope cancel now?". Here is the collecting joiner from the JEP, fleshed out so it compiles as-is:
class CollectingJoiner<T> implements Joiner<T, List<T>> {
private final Queue<T> results = new ConcurrentLinkedQueue<>();
@Override
public boolean onComplete(Subtask<T> subtask) {
if (subtask.state() == Subtask.State.SUCCESS) {
results.add(subtask.get());
}
return false; // never cancel early — let everyone finish
}
@Override
public void onTimeout() {
// called if the scope was opened with a timeout that fired
System.out.println("Timeout expired — returning what we have");
}
@Override
public List<T> result() {
return List.copyOf(results);
}
}Two things matter here. First, onComplete can be called concurrently by several subtask threads, so the joiner must be thread-safe — that’s why results go into a ConcurrentLinkedQueue. Second, Subtask.state() reports one of three values: SUCCESS, FAILED, or UNAVAILABLE (forked but not completed, or completed after the scope was cancelled). Use it instead of calling get() blindly. Reuse rule: create a fresh Joiner for every scope — never share one across scopes or reuse it after a scope closes.
Observability: see the hierarchy in a thread dump
Remember the original complaint — a thread dump of the unstructured version showed three unrelated threads with no hint they belonged together. Structured concurrency fixes that too. Generate a JSON thread dump while your program runs:
$ jcmd <pid> Thread.dump_to_file -format=json threads.jsonEach scope appears as a container that lists the threads forked inside it and a reference to its parent scope, so tools can reconstruct the exact task tree:
{
"container": "orders/jdk.internal.misc.ThreadFlock$ThreadContainerImpl@44c794fd",
"parent": "<root>",
"owner": "3",
"threads": [
{ "tid": "36", "virtual": true, "name": "RandomTask-0" },
{ "tid": "38", "virtual": true, "name": "RandomTask-1" }
]
}This is the observability payoff of the whole model: the runtime hierarchy mirrors your code’s block structure, so "what is this request working on right now?" becomes answerable for concurrent code, not just single-threaded code.
Scope hierarchies and scoped values
Because a subtask can itself open a StructuredTaskScope and fork its subtasks, scopes nest into a tree that mirrors your method calls. The lifetime rule composes cleanly: a child scope’s threads are all terminated before the child scope closes, which happens before the parent scope closes. Cancellation flows down that tree automatically.
Subtasks also inherit ScopedValue bindings (JEP 487). If the owner binds a scoped value — say, the current request ID or principal — every forked subtask reads the same value, with none of the mutability hazards of ThreadLocal. Structured concurrency and scoped values are designed as a matched pair: one carries immutable context down into the subtasks, the other carries structure and lifetime.
Structured concurrency vs. CompletableFuture
A fair question for experienced readers: don’t we already have CompletableFuture? They solve different problems, and the distinction is the whole point of the feature:
CompletableFutureis for the asynchronous, non-blocking style: you compose callbacks (thenApply,thenCompose,exceptionally) into a pipeline, and tasks may outlive the method that created them. It’s powerful but the lifetime is unbounded and error/cancellation handling is manual.StructuredTaskScopeis for the blocking, structured style: fork, block once injoin(), then handle results and errors centrally. Lifetimes are confined to a lexical block, and cancellation is automatic.
With cheap virtual threads, "just block" is no longer expensive, so the structured/blocking style gives you most of the throughput with far less cognitive load. The JEP is explicit that structured concurrency is not meant to replace ExecutorService, Future, or CompletableFuture — reach for it when your tasks have a genuine parent-child relationship and should live and die together.
Migrating from ExecutorService
You don’t need a rewrite. The mechanical translation is: replace the ExecutorService (used in a try-with-resources) with a StructuredTaskScope, replace submit(...) with fork(...), add a single join() before you read results, and replace future.get() with subtask.get(). The payoff is that thread leaks and manual cancellation simply disappear, because the scope enforces structure at runtime — forking from a non-owner thread or leaving the block without closing throws a StructureViolationException rather than silently corrupting your task tree.
Best practices and gotchas
A short checklist distilled from everything above:
- Enable preview, target JDK 26: compile with
javac --release 26 --enable-previewand run withjava --enable-preview(orjshell --enable-previewto experiment). - One
join()per scope, by the owner thread. Don’t readSubtask.get()before joining. - A new
Joinerper scope. Never reuse or share joiner instances. - Make subtasks interruptible. A subtask that ignores interrupts (e.g. blocks on a non-interruptible call) can delay
close()indefinitely, becauseclose()always waits for threads to actually terminate. - Let exceptions flow, handle them after the block. Use a
catch (FailedException e)on the try-with-resources and pattern-matche.getCause(). - Don’t pass a scope to code that expects an
ExecutorService.StructuredTaskScopedeliberately does not implementExecutorService, precisely because that interface is used in unstructured ways.
Version history and current status
Structured concurrency has had an unusually long, careful incubation — useful context when you read older tutorials whose API no longer matches:
| Release | JEP | Note |
|---|---|---|
| JDK 19 / 20 | 428 / 437 | Incubator |
| JDK 21 | 453 | First preview; fork returns Subtask (not Future) |
| JDK 22 / 23 / 24 | 462 / 480 / 499 | Re-previews |
| JDK 25 | 505 | Big API change: constructors replaced by static open(...) factories; Joiner introduced |
| JDK 26 | 525 | allSuccessfulOrThrow() now returns a List; anySuccessfulResultOrThrow renamed to anySuccessfulOrThrow; Joiner.onTimeout() added |
| JDK 27 (expected) | — | Likely finalization |
If you’re starting today on JDK 25 or 26, learn the open(...) + Joiner API shown here; the pre-JDK-25 ShutdownOnFailure / ShutdownOnSuccess classes you may see in older posts are gone.
Quick reference
// Core shape (JDK 26 preview)
sealed interface StructuredTaskScope<T, R> extends AutoCloseable {
static <T> StructuredTaskScope<T, Void> open();
static <T,R> StructuredTaskScope<T, R> open(Joiner<? super T, ? extends R> joiner);
static <T,R> StructuredTaskScope<T, R> open(Joiner<? super T, ? extends R> joiner,
UnaryOperator<Config> configFn);
<U extends T> Subtask<U> fork(Callable<? extends U> task);
Subtask<? extends T> fork(Runnable task);
R join() throws InterruptedException; // throws FailedException / TimeoutException per joiner
void close();
}
// Built-in joiners
Joiner.awaitAll(); // Void, never throws
Joiner.awaitAllSuccessfulOrThrow(); // Void, throws on first failure
Joiner.allSuccessfulOrThrow(); // List<T> of results
Joiner.anySuccessfulOrThrow(); // T, first success wins (race)
Joiner.allUntil(predicate); // List<Subtask<T>>
// Config
cf -> cf.withName("...").withTimeout(Duration.ofMillis(...)).withThreadFactory(factory);
// Subtask
subtask.get(); // result after join(); like Future.resultNow()
subtask.state(); // SUCCESS | FAILED | UNAVAILABLEClosing thought
Structured concurrency is a small API with a big idea: concurrency should be as readable and reliable as a method call. You write what looks like ordinary blocking code; the runtime gives you parallel execution, automatic cancellation, clean error propagation, and a thread dump that finally makes sense. Start with open() and join() for the 80% case, reach for a Joiner when you need a race or a collection, and write a custom joiner only when your policy is genuinely your own. With virtual threads underneath, this is how concurrent Java is meant to be written from here on.