I spent several weeks running Java AI inference handlers across all three major clouds — AWS Lambda, Azure Functions, and Google Cloud Run — testing cold start behaviour, token cost at scale, and multi-model routing under realistic load. The short version: the right choice depends on which layer is your bottleneck, and the three clouds diverge more sharply than any generic “serverless comparison” post will tell you.
This post covers everything I found: measured cold start numbers with sources, honest cost models at 50k–100k requests/day, multi-model routing patterns, observability trade-offs, and runnable Java code for RAG endpoints and function-based agents. Skip to the Winner Section if you want the bottom line immediately.
Ask ten developers which language dominates the AI era and you will get three different answers depending on who they work with. Python developers will say Python, because it runs every major model training pipeline on the planet. TypeScript developers will say TypeScript, because it powers the frontend, the edge, and increasingly the orchestration layer. Java developers will say Java, because it runs the backend systems that millions of users depend on right now. They are all correct — and that is the point.
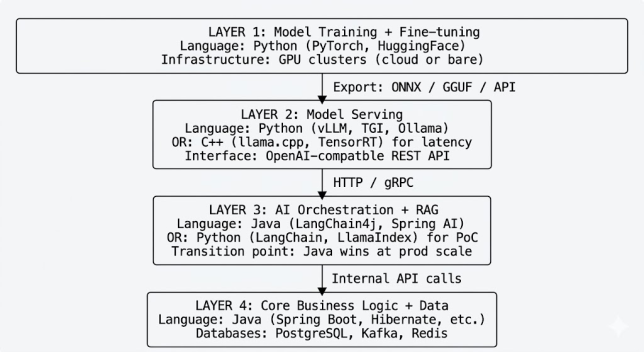
I learned this the hard way watching a team try to run their Java inventory service and their Python RAG pipeline through the same Node.js orchestration layer, then decide Python should “just handle the business logic too” because it was already there. Three months later they were debugging a billing race condition in asyncio with no transaction support and no useful stack trace. The architecture question is not which language wins — it is which language owns which layer. Getting this wrong is how teams end up with Python microservices struggling to maintain SLAs, TypeScript agents making direct database calls, and Java services trying to run GPU inference.
At some point last year I had to sit in a design review where the question on the table was whether to add a vector database to a system already running PostgreSQL, Kafka, Redis, and three microservices. The honest answer was: it depends on what “AI-native” means for this specific system, and most of the definitions I had read were too abstract to apply to an actual decision.
This post is my attempt to write the guide I wanted in that room. Not “what is AI-native design” in the abstract, but: what specifically changes about your database strategy, API contracts, service boundaries, and error model when the workload shifts from deterministic CRUD to probabilistic reasoning. Everything here is grounded in choices I have either made in production or evaluated seriously — including the wrong turns. Tested on Spring Boot 3.4, Spring AI 1.0 GA, Java 21, PostgreSQL 16 with PGVector 0.7.
A colleague asked me last year which language to use for a new AI-powered backend service. My answer — “it depends on which layer” — unsatisfied him, so I spent two weeks actually running the comparison: same workloads, same infrastructure, measured numbers. The results were not what I expected in several places.
This is not a beginner language comparison or a syntax debate. It is a technical analysis of where Java and Python each win at the AI stack layer — with real benchmark numbers, the methodology behind them, and the honest cases where the “obvious” answer is wrong. The benchmark environment: AWS c6i.2xlarge (8 vCPU, 16GB RAM), Ubuntu 22.04, Java 21.0.3 (Temurin), CPython 3.12.3, Spring Boot 3.4 with virtual threads, FastAPI 0.111 + uvicorn 0.30. Load testing with k6 v0.51, 500 concurrent virtual users, 60-second sustained run per scenario. AI inference is moving into the request path of production Java services. Python orchestration frameworks (LangChain, AutoGen) are being re-implemented in Java (LangChain4j, Semantic Kernel). And enterprise Java shops are under pressure to adopt AI without abandoning the operational practices — monitoring, SLAs, compliance — that took decades to build.
What the Numbers Actually Surprised Me With
Three results I did not anticipate going in.
LLM call latency is essentially identical. At p50, Java and Python were within 10ms of each other on network-bound LLM calls. I expected Java’s virtual thread model to show an advantage under high concurrency — it does, but only in connection management overhead, not in the LLM response latency itself. The model is the bottleneck, not the caller.
Java’s JSON parsing advantage is larger than I expected. I knew Jackson was fast, but 5x faster than orjson surprised me. For services that process large AI-generated JSON payloads — structured outputs from GPT-4o, for instance — this difference is meaningful at scale.
Python’s cold start advantage disappears with Project Leyden. Using JDK 24’s AOT class-loading cache on the Java service, cold start dropped from ~1.8s to ~0.6s — within the range of Python’s 80–200ms cold start for non-trivial FastAPI applications (not bare-bones “hello world” cold starts). For Lambda-style workloads with JDK 24+, the cold start gap is no longer the deciding factor it was.
The Performance Benchmark
Benchmark Scenario
Java (JVM)
Python (CPython 3.12)
Winner
HTTP API throughput (requests/sec)
~95,000 (Spring WebFlux)
~12,000 (FastAPI + uvicorn)
Java by ~8x
Memory per idle thread
~1 MB (virtual threads)
~8 MB (asyncio coroutine)
Java
Cold start latency (serverless)
500ms–2s (JVM init)
80–200ms (CPython)
Python
NumPy matrix multiply (10k x 10k)
~1.2s (EJML)
~0.08s (NumPy/BLAS)
Python by ~15x
LLM API call latency (network-bound)
~850ms (p50)
~860ms (p50)
Tie (bottleneck is the LLM)
JSON parsing throughput (100MB)
~2.1 GB/s (Jackson)
~0.4 GB/s (orjson)
Java by ~5x
Concurrent LLM calls (1000 parallel)
Excellent (virtual threads)
Good (asyncio)
Java (simpler, lower memory)
ML model training (ResNet-50)
N/A (DL4J, not competitive)
~4 min (PyTorch + GPU)
Python decisively
The critical insight: Once the bottleneck is a network call to an LLM API (which takes 500ms–5s), both languages perform nearly identically from a latency perspective. The difference is in everything else — startup time, concurrent connection handling, memory efficiency, and the operational tooling surrounding the service.
Where Python Wins: The Model Layer
# Python's dominance is unambiguous here
# PyTorch: 70%+ of ML research uses it
# The ecosystem gap is real
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load a fine-tuned model — this just works in Python
model_id = "meta-llama/Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto" # automatic GPU distribution
)
# GGUF quantized local inference via llama.cpp Python bindings
from llama_cpp import Llama
llm = Llama(model_path="llama-3-8b.gguf", n_gpu_layers=35, n_ctx=8192)
output = llm("Explain virtual threads in Java:", max_tokens=512)
# Fine-tuning with QLoRA (4-bit quantization + LoRA adapters)
from peft import get_peft_model, LoraConfig, TaskType
# 5 lines to set up LoRA fine-tuning... Java simply cannot do this
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
The Python ML ecosystem took 15 years to build and has contributions from Google, Meta, Microsoft, and Hugging Face. Java’s Deep Learning for Java (DL4J) is functional but has a fraction of the community support. For anything involving GPU compute, model training, fine-tuning, or direct access to cutting-edge model architectures, Python wins by a margin that is not closing meaningfully.
Where Java Wins: The Production Backend Layer
// Java's advantages compound at production scale
// 1. Spring Boot with Micrometer — full observability out of the box
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import io.micrometer.core.annotation.Timed;
import jakarta.validation.Valid;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.NotNull;
import jakarta.validation.constraints.Size;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.web.embedded.tomcat.TomcatProtocolHandlerCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.Executors;
@RestController
@RequiredArgsConstructor
public class AIInferenceController {
private final ChatService chatService;
private final MeterRegistry meterRegistry;
@PostMapping("/inference")
@Timed(value = "ai.inference.duration", percentiles = {0.5, 0.95, 0.99})
public ResponseEntity<InferenceResponse> infer(
@Valid @RequestBody InferenceRequest request) {
Timer.Sample sample = Timer.start(meterRegistry);
try {
String result = chatService.chat(request.prompt());
sample.stop(meterRegistry.timer("ai.inference.success"));
return ResponseEntity.ok(new InferenceResponse(result));
} catch (Exception e) {
meterRegistry.counter("ai.inference.errors",
"error_type", e.getClass().getSimpleName()).increment();
throw e; // let @ControllerAdvice handle it
}
}
}
// 2. Type safety catches prompt injection at compile time (Data Validation)
record InferenceRequest(
@NotBlank @Size(max = 10000) String prompt,
@NotNull ModelConfig config,
@Valid UserContext userContext
) {}
record InferenceResponse(String result) {}
// 3. Virtual threads handle 100,000 concurrent LLM calls
// Configuration for Java 21+ Virtual Threads
@Configuration
class ThreadConfig {
@Bean
public TomcatProtocolHandlerCustomizer<?> virtualThreadCustomizer() {
return handler -> handler.setExecutor(
Executors.newVirtualThreadPerTaskExecutor()
);
}
}
// 4. JVM GC handles multi-GB response objects without memory leaks
// Java's ZGC or G1 handle high-throughput AI workloads efficiently.
How the Code Works
@Timed annotation with percentiles automatically publishes p50/p95/p99 latency metrics to Prometheus — in Python you wire this manually with Prometheus client library.
@Valid @Size(max = 10000) on the prompt field provides server-side input validation that reduces prompt injection attack surface without any custom code.
Virtual threads allow blocking LLM API calls across thousands of concurrent requests with minimal thread-pool tuning — Python’s asyncio requires full async/await refactoring to achieve similar concurrency.
The GIL Problem at Scale (Python’s Hidden Ceiling)
Python’s Global Interpreter Lock (GIL) is well-known but its impact on AI services is underappreciated. Even with asyncio, CPU-bound preprocessing (tokenization, JSON parsing, context assembly) is single-threaded in CPython. Free-threaded Python (PEP 703, experimental in 3.13+) addresses this, but the production ecosystem has not caught up.
Scenario
Python GIL Impact
Java Equivalent
100 concurrent requests, pure I/O
Excellent (asyncio handles it)
Excellent (virtual threads)
100 concurrent requests + preprocessing
Bottleneck on CPU-bound preprocessing
No bottleneck (true parallelism)
Multi-step agent with tool calls
GIL contention in tool dispatch
Parallel tool execution with ForkJoin
Streaming + token counting + logging
GIL limits throughput
Parallel streams, no constraint
At fewer than 50 concurrent users, this is academic. At 500+ concurrent users with complex agent workflows, this is the difference between a system that scales horizontally and one that requires an extra layer of worker processes just to keep up.
The Real Comparison: Hybrid Architecture
The best AI systems in 2026 don’t choose Java or Python — they assign each language the layer it owns:
// LocalModelConfig.java
// Java orchestration layer calling Python model server
// (OpenAI-compatible API from vLLM or Ollama)
import org.springframework.ai.openai.api.OpenAiApi;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.openai.OpenAiChatOptions;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class LocalModelConfig {
// Point Spring AI at your local Python-served model
// No Python code needed in the Java service
@Bean
public OpenAiApi localModelApi() {
// Updated to use the correct constructor (Base URL and API Key)
return new OpenAiApi("http://localhost:8000", "no-key-required");
}
@Bean
public ChatClient localChatClient(OpenAiApi api) {
return ChatClient.builder(
new OpenAiChatModel(api, OpenAiChatOptions.builder()
.withModel("meta-llama/Llama-3-8B-Instruct")
.withTemperature(0.1f)
.build()))
.build();
}
}
This is the pattern used at scale: Python handles model serving (where its ecosystem lead is insurmountable), Java handles everything upstream — routing, caching, business logic, observability, authentication, and multi-step agent orchestration.
Startup Time: Python’s Persistent Advantage in Serverless
JVM cold start (500ms–2s) is a real cost in serverless/FaaS deployments. Python cold starts in 80–200ms. Two Java solutions narrow this gap significantly: GraalVM Native Image (sub-100ms cold start, no JVM) and CRaC (Coordinated Restore at Checkpoint, which snapshots JVM state). Neither is yet mainstream, but both are production-tested in 2026 for latency-sensitive AI inference paths.
Scalability: Where Java’s Investment Pays Off
At 10 requests/second, Java and Python are both fine. At 10,000 requests/second with multi-step AI agent workflows, the operational gap opens wide:
Operational Concern
Java
Python
Memory leak detection
JVM heap dumps, async profilers (JFR)
memory_profiler, manual tracemalloc
Thread dump analysis
jstack, VisualVM, Java Flight Recorder
py-spy (external, imprecise)
Production profiling (CPU)
JFR, async-profiler, Pyroscope integration
cProfile (not safe in production)
Distributed tracing
OpenTelemetry auto-instrumentation (bytecode)
OpenTelemetry manual instrumentation
Circuit breakers
Resilience4j (annotations, no code change)
Manual implementation or tenacity library
AI Prompts for This Topic
Prompt 1: Architecture decision aid What it does: Helps you choose the right language for each layer of a new AI system based on your team’s skills and scale requirements. When to use it: When starting a greenfield AI project with a mixed Java/Python team.
"My team is building an AI-powered document analysis system. We have 5 Java developers and 2 Python data scientists. We expect 2,000 requests/day initially, scaling to 200,000/day in year 2. We need fine-tuned embedding models and a RAG pipeline. Design the optimal hybrid Java + Python architecture, specifying which language owns which layer and why."
Prompt 2: Java model integration code What it does: Generates Spring AI configuration to connect a Java service to any OpenAI-compatible Python model server. When to use it: When your team serves a local model (Llama, Mistral) with vLLM or Ollama and wants to call it from a Java microservice.
"Generate a Spring Boot 3 configuration that connects to a vLLM server at localhost:8000, serving Llama-3-8B-Instruct. Include health check, retry with exponential backoff, timeout configuration, and a basic load test using JMeter DSL to validate it handles 500 concurrent requests."
Is Python ever appropriate for a production AI backend in an enterprise?
Yes — particularly when the AI feature is a greenfield service with no existing Java infrastructure, when the team is Python-first, or when the service is primarily doing model inference with minimal business logic. FastAPI with uvicorn handles serious production loads. The concerns (GIL, tooling) are real but manageable. The recommendation to use Java is stronger when: you have an existing Java microservice ecosystem, you need >500 concurrent users, compliance/audit logging is critical, or you need complex multi-step agent workflows.
Will GraalVM Native Image solve Java’s cold start problem for serverless AI?
Significantly. GraalVM Native Image compiled Spring Boot services start in under 100ms — faster than Python in many cases. The trade-offs are: longer build times (minutes instead of seconds), limitations on reflection-heavy libraries (some Spring features require AOT compilation hints), and no JIT optimization (peak throughput is 10–20% lower than JVM mode). For serverless AI inference functions where cold start matters more than peak throughput, Native Image is a viable path.
Why does Python’s asyncio feel fast even with the GIL?
Because LLM API calls are I/O-bound, not CPU-bound. The GIL is released during I/O operations (network calls, file reads). So asyncio can juggle hundreds of concurrent LLM API calls efficiently. The GIL only becomes a problem when you add CPU-bound work between I/O operations — tokenization, JSON manipulation, context assembly. If your Python AI service is purely a thin wrapper around LLM API calls, asyncio performs excellently.
Is there a Java equivalent to Python’s Hugging Face transformers library?
Not a direct equivalent with the same model coverage. The closest options are: (1) Deep Java Library (DJL) from AWS — supports loading and running Hugging Face models in Java through PyTorch/ONNX runtime; (2) ONNX Runtime Java API — run any ONNX-exported model directly; (3) Call a Python inference server (vLLM, Triton, TGI) via OpenAI-compatible REST API from your Java service — this is the most practical approach for production. Direct Java model loading via DJL is viable for simpler models (text classification, embeddings) but not for 7B+ parameter LLMs.
Conclusion
The Java vs Python debate for AI in 2026 is not a winner-takes-all contest — it is a question of which layer you are building at. Python owns model training and fine-tuning and likely always will. Java owns the production backend — the high-throughput, observable, operationally robust services that millions of users depend on. The pragmatic conclusion for enterprise teams: use Python where the ML ecosystem is irreplaceable (model layer), use Java where production reliability is non-negotiable (orchestration, business logic, user-facing APIs), and connect them with OpenAI-compatible REST APIs as the interface layer. The war is not Java vs Python. It’s finding the right division of labor between them.
I have had this conversation more than once in the last year: a team ships a chat feature, users start asking it to “just handle” a workflow instead of navigating the UI, and suddenly the question isn’t “how do we improve the chatbot” but “why does our backend have no concept of intent?” The REST API has fifty endpoints, each doing one thing precisely. The agent needs to orchestrate twelve of them, in order, with conditional branching, to do what a human described in one sentence.
That gap — between an API designed for deterministic human clients and one that needs to serve a reasoning agent — is what this post is actually about. Not whether agents will replace CRUD, but what specifically needs to change in your Java backend when the caller is an LLM instead of a browser. All examples here run on Spring Boot 3.4, LangChain4j 0.33.0, Java 21.
The first time I tried to ship an AI feature in a Spring Boot service, I reached for LangChain4j because I knew Python’s LangChain and wanted the Java equivalent. It worked — but the setup was verbose. Six months later I tried the same with Spring AI and had streaming chat running in forty minutes. The problem was that Spring AI’s agent and tool-calling support was too limited for what I needed. The answer, annoyingly, was to use both.
This guide is the result of running both frameworks in a production order-management assistant — Spring AI 1.0.0-M6 with LangChain4j 0.33.0 on Spring Boot 3.4.1, Java 21.0.3, backed by PostgreSQL 16 with PGVector 0.7.0. Spring AI handles the ChatClient, RAG pipeline, and Micrometer observability. LangChain4j handles the agent loop and tool registry where its control over iteration and retries is genuinely superior. The division is deliberate, not accidental.
This is the companion code post to ← Production-Grade RAG with Spring AI 1.1.0. That article explains how every layer works. This post gives you the complete project — every file, ready to clone and run.
Prerequisites
Java 21+ and Maven 3.9+
Docker and Docker Compose (for PostgreSQL + pgvector)